Note: This post assumes a passing familiarity with linear regression. Aside from that, it’s a highly applied intro to D-in-D regression and panel data techniques.
In Due Time
In one of my favorite episodes of Futurama, the universe experiences “time skips.” During a time skip, the screen goes black, and our heroes are hurled into the future and into increasingly zany situations (e.g., mid-limbo contest).
The episode’s central dilemma (aside from the looming end of the universe) is that no one can actually remember what happens during a skip. For example, after one universal black-out, Leela and Fry — the series’ will-they/won’t-they couple — end up married. At this point, Leela can’t imagine marrying Fry, so she assumes he tricked her, and promptly files for divorce.
Tragically, we later learn that she really did want to marry Fry: She’d been won over by a Grand Romantic Gesture he’d put together during the offending skip.
What could possibly be the point of this story? Aside from being a cry for help for an editor, it’s this: Doing Data Science can be equally perilous, time-wise. Indeed, if you ignore the time component of your analyses, you may find effects where none exist — or miss gigantic, wedding-sized effects where they do.
To ensure you don’t end up doing your own intergalactic limbo, we’re going to learn how to use powerful econometric methods — difference-in-differences regression and panel data techniques — to incorporate time into your analytical worldview.
These techniques are particularly useful because they allow you to run “quasi-experiments,” i.e., studies you can interpret causally even when you can’t randomly assign your subjects into treatment and control groups. This causal interpretation will undoubtedly require extra assumptions beyond those of your typical A/B test, but often, A/B tests aren’t feasible due to real-world constraints — technical, ethical, or otherwise.
Oh, and don’t be intimidated by all this talk of causality. While causal inference in econometrics has a rich philosophical and mathematical underpinning, in practice it boils down to this: how to do clever things with regression0.
(A quick note: I normally use Python, but since I want to make this broadly accessible for the #rstats crowd, I’ll do some of this in R as well. Note that it’s easy to combine the two using rpy2, as I do in the notebook behind this post.)
Part 0: The Scenario and Intuition
Theoretical statistical formulations don’t do much for me, so let’s keep this as applied as possible. For the rest of this post, we’re going to consider the following problem:
We work at {ONLINE_EDUCATION_PLATFORM}. We have a bunch of {UNIQUE_ONLINE_CLASSES}, and we’ve recently discovered a Wonderful New Intervention (“WNI”) that we think improves {LEARNER_MASTERY} (“LM”).
On a given day (let’s call it “Launch Day”), some professors modified their classes to incorporate our WNI, but others were too busy and promised they would get to it later.
Consequently, we now have two groups of classes on our platform — those that have our WNI and those that don’t.
This begs the question: “How can we rigorously gauge the effect of our WNI on Learner Mastery?”1
The simple answer:
- (A) First, we’ll see how much our WNI seemed to improve Mastery in classes where it was rolled out (i.e., our “quasi-treatment” group). This is easy: We simply take all such classes and subtract their average “pre” Launch Day scores from their average “post” Launch Day scores.
- (B) And while it may be tempting to stop here, this “Naive Treatment Difference” may mislead! For example, what if Launch Day happened in January, when learners may be more motivated to master material and live up to their New Year’s Resolutions? We may think our WNI had improved things, but really, we’d be taking credit for fundamental changes in our learner population. Here, our Naive Treatment Difference would be an overestimate of the WNI effect.
- (C) This is where our “control” group comes in. We’ll now look to see how Mastery changed in classes where our WNI wasn’t rolled out by repeating step (A) for all such classes. Namely, we’ll subtract their average “pre” Launch Day scores from their average “post” Launch Day scores. In theory, this difference explains what would have happened to our treatment group had the WNI never happened.
- (D) We now have two differences: our “Control Difference” from (C); and our “Naive Treatment Difference” from (A).
- (E) Under an assumption known as “parallel trends” (which we get to shortly), we can calculate the “Real” WNI Treatment Effect by subtracting the former from the latter. In theory, this final difference “removes” the part of the Naive Treatment Difference that is caused by non-WNI-related changes on our platform (e.g., New Year’s Resolutions; new learner populations; people getting smarter; etc.).
- (F) In other words, this “Difference in Differences” (get it?) reports the “real” effect of our WNI!2
So if things get dicey, just remember that the rest of this post is merely a statistical spin on (A) – (F).
This section is our Intuitive North Star.
Alright, this has been a lot of talking. Let’s get to the good stuff.
Part 1: The Data
First, let’s generate some data with the properties we want. The code includes extensive comments to explain what’s happening, but in words:
- We’re going to generate data for 50 classes, and for each class, we’re going to simulate Learner Mastery scores for 10 months: 5 months before Launch Day and 5 months after Launch Day. (Please note: The number of time periods on either side of the WNI doesn’t need to be equal — I’m just trapped in the ideological confines of our Base 10 Number System.)
- This means we’ll have a total of 500 observations in our data set (50 classes by 10 months). #BigData
- We’re going to assume that for any given class, Learner Mastery scores are normally distributed around some mean value. For each class, we’ll generate this mean value from a uniform distribution between 50 and 80, and then sample from the resulting normal distribution 10 times — once for every month.
- For classes that do get our WNI, we’ll assume that their post-Launch Day LM scores go up by 8
- For classes that don’t get our WNI, we’ll assume that their post-Launch Day LM scores go up by only 3
- Note, then, that the “real” effect of our WNI should on average be around 5 Learner Mastery points (to see this, subtract the 3-point “control difference” from our 8-point “naive treatment difference”).
- (Note that due to randomness, the WNI effect in our example actually comes out to 6.14)
- I do some other things to make it slightly more real-world. In particular, I include some month-specific effects and add some autocorrelation to individual classes (for now, don’t worry about this last point: We return to it in Part 5)
Translated to code:
def generate_dd_data(num_classes=50, low_lm=50, high_lm=80, var_lm=5, random_seed=10900):
np.random.seed(random_seed)
# set up our Data Frame with the necessary columns
result = pd.DataFrame(columns=['class_number',
'month',
'post_launch_day',
'received_wni',
'avg_learner_mastery'])
# we want to generate 10 months worth of data for every class
months = pd.date_range('2016-01-01', '2016-10-01', freq='MS')
num_months = len(months)
# we want to include month-specific effects
month_effect = [10, 5, -10, -5, 0, 0, -5, -10, 10, 5]
# the first five months correspond to observations before Launch Day,
# and the next five months correspond to observations after Launch Day
wni_launched = np.array([0, 0, 0, 0, 0, 1, 1, 1, 1, 1])
# for every class...
for i in xrange(num_classes):
# Average Learner Mastery for every class will be normally distribution around some
# mean; this mean will be drawn from the following uniform distribution...
avg_learner_mastery_of_this_class = np.random.randint(low_lm, high_lm)
# ...and then observations will be taken
avg_lm_scores = np.random.normal(avg_learner_mastery_of_this_class, var_lm, num_months)
# We'll randomly assign each class to the treatment and control groups
if np.random.rand() < .5:
received_wni = 1
# If it's in the treatment group, then the class will improve by an average of 8
# Learner Mastery points after Launch Day
lm_boost = np.random.normal(8, 2, num_months)*wni_launched
# We're also going to give all treatment classes a 5-point Learner Mastery
# boost because we assume they're naturally better somehow (perhaps because they're
# taught by more motivated instructors)
lm_boost += np.random.normal(5, 1, num_months)
else:
received_wni = 0
# If it's in the control group, then the class will improve by an average of 3
# Learner Mastery points after Launch Day (this could be for any number of reasons, but
# let's just assume we somehow got more motivated learners on the platform)
lm_boost = np.random.normal(3, 1, num_months)*wni_launched
# Increase average learner mastery scores from above by the "boost" we just calculated
avg_lm_scores += lm_boost
# Add month-specific learner mastery effects (e.g., January will be 10 points higher across all
# all classes, since learners are more motivated at the beginning of the year)
avg_lm_scores += np.random.multivariate_normal(month_effect, np.identity(10))
# Add an ARMA process to make this examle more real-world
avg_lm_scores += sm.tsa.arma_generate_sample([1, -.2, -.1], [1], nsample=10)
tmp_frame = pd.DataFrame({
'class_number': 'Class ' + str(i),
'month': months,
'post_launch_day': wni_launched,
'received_wni': received_wni,
'avg_learner_mastery': avg_lm_scores
})
result = result.append(tmp_frame)
return result
df = generate_dd_data()
df.head()
| avg_learner_mastery | class_number | month | post_launch_day | received_wni | |
|---|---|---|---|---|---|
| 0 | 77.487571 | Class 0 | 2016-01-01 | 0.0 | 1.0 |
| 1 | 67.069682 | Class 0 | 2016-02-01 | 0.0 | 1.0 |
| 2 | 51.744760 | Class 0 | 2016-03-01 | 0.0 | 1.0 |
| 3 | 60.313582 | Class 0 | 2016-04-01 | 0.0 | 1.0 |
| 4 | 69.690571 | Class 0 | 2016-05-01 | 0.0 | 1.0 |
Now that we have data, we can get modeling, right?
Part 2: Vetting Assumptions
Wrong!
As mentioned earlier, the critical assumption when doing this kind of analysis is known as “parallel trends” — the idea that, in the absence of our WNI, the average change in mastery for our treatment group would have been the same as the average change in mastery for our control group.
By definition, we can never prove this assumption. We’ll never be able to observe our counterfactual world and see what would have happened to our treatment group without the WNI.
That said, even if a proof is impossible, we can at least get comfortable with the idea. And since I’m a simpleton, my preferred method for developing such comfort is visualization.
In Python:
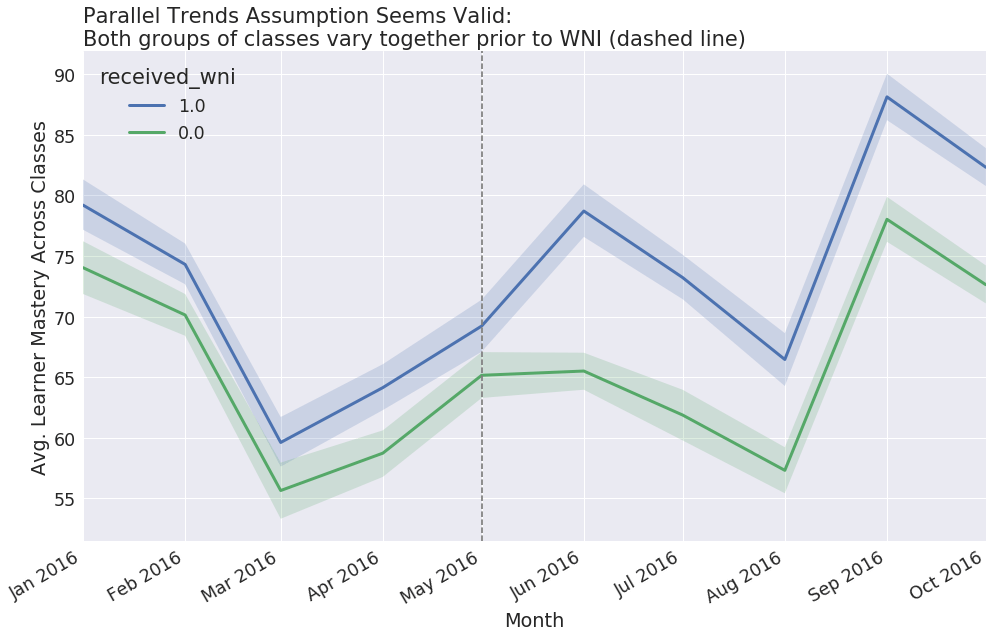
fig, ax = plt.subplots(1, 1, figsize=(16.18, 10))
sns.tsplot(time='month', value='avg_learner_mastery', unit='class_number', condition='received_wni',
data=df, ax=ax, lw=3)
ax.set_title('Parallel Trends Assumption Seems Valid:\nBoth groups of classes vary together prior to WNI (dashed line)', loc='left')
ax.set_xlabel('Month')
ax.set_ylabel('Avg. Learner Mastery Across Classes')
fig.autofmt_xdate()
# x-axis comes as integer by default...
int_months = df.month.unique().astype(np.int64)
ax.set_xticks(int_months)
ax.set_xticklabels(pd.Series(df.month.unique()).apply(lambda x: pd.datetime.strftime(x, '%b %Y')))
ax.axvline(int_months[4], ls='dashed', color='grey')

And in R:
df = df %>%
mutate(received_wni = factor(received_wni),
month = as.Date(month))
dfg = df %>%
group_by(month, received_wni) %>%
summarize(avg_learner_mastery = mean(avg_learner_mastery))
dfg %>%
ggplot(aes(month, avg_learner_mastery, color = received_wni)) +
geom_line(aes(group = class_number), df, alpha = 0.5, size = 0.25) +
geom_line(size = 2.0) +
geom_vline(xintercept = as.numeric(as.Date('2016-05-01')), linetype = "dashed") +
xlab("Month") +
ylab("Avg. Learner Mastery Across Classes") +
labs(title = "Parallel Trends Assumption Seems Valid",
subtitle = "Both groups of classes vary together prior to WNI (dashed line)")
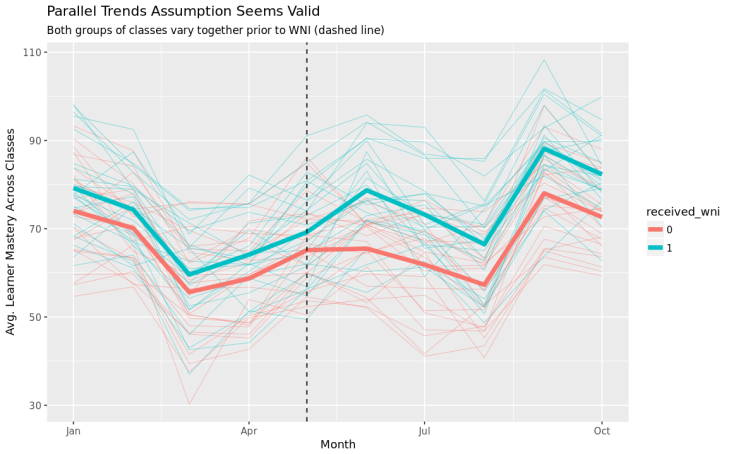
Here, we see that prior to our intervention (marked by the dashed line), average Mastery scores for both our treatment and control groups varied from month-to-month in a very similar way. As such, it might not be crazy to think that they would have continued to vary in a similar way if not for our WNI.
Important aside: Never trust a difference-in-differences analysis that doesn’t show you a similar graph!
(Parenthetical aside: There are other ways to vet our parallel trends assumption. These techniques can be particularly helpful when we’re dealing with the more complex models we’ll encounter later.)
Part 3: The World’s Simplest, Dumbest Model (a.k.a., the “Regression Version” of our Intuitive North Star)
All of our regression models — even the most complicated ones — will look something like this:
Learner Mastery ~ “Post-Launch Day” + “Received WNI” + “Post-Launch Day”*”Received WNI” + {Other Regressors, e.g., to improve precision of estimates}
Or in code…
# we're using Python's statsmodels library and referring
# to it as smf
smf.ols('avg_learner_mastery ~ post_launch_day + received_wni + post_launch_day:received_wni', dfg).fit()
But what is this model actually doing? We know that it should be returning the “real” estimate of our WNI Treatment Effect, but it may hard to see this straight away. To figure out what’s going on at an intuitive level, let’s aggregate our data set into two time periods (“pre-LD” and “post-LD”) and two groups (“received WNI” and “did not receive WNI”):
# grouping by our original data frame and taking the mean dfg = df.groupby(['received_wni', 'post_launch_day']).mean().reset_index()
Our once mighty data set is now only four rows long:
| received_wni | post_launch_day | avg_learner_mastery | |
|---|---|---|---|
| 0 | 0.0 | 0.0 | 64.733482 |
| 1 | 0.0 | 1.0 | 67.064582 |
| 2 | 1.0 | 0.0 | 69.291525 |
| 3 | 1.0 | 1.0 | 77.768548 |
However, just because it’s small doesn’t mean we can’t fit the model we discussed above. If we do, we’ll get the following regression summary. (Don’t be thrown by all the nan’s! We can’t calculate valid standard errors because there are only four rows, but this model is for illustrative purposes only):

Hmmm — I remember we said that the treatment effect of our WNI should be around 5 (or in our case, exactly 6.1459). It looks like the last row of the regression summary — the one which corresponds to the interaction term — is equal to 6.1459. Is this our treatment effect?!
Yes!
To fully grok this, let’s think about what this regression equation is actually doing — step-by-step:
(I) The Intercept
What does the “intercept” term of our regression mean? Pedantically, it means that all regressors are set to zero, or less pedantically, it means that (A) “post-Launch Day” is set to zero; and (B) “received WNI” is set to zero. Thus, we’re looking at observations that come from the control group prior to Launch Day.
Since it’s a regression, we’re going to calculate the average mastery score for all such observations; however, we only have four rows in our data set! Consequently, our “average” score is simply the mastery score of our very first row — the only observation that corresponds to this set of criteria.
(II) The Control Difference
Moving on: What if “post-Launch Day” is one but “received WNI” is zero?
In this case, we’re considering all observations from our control group that occurred after Launch Day. But here again, we have only a single row that corresponds to these criteria — the second row of our data set.
Since this is a regression, this coefficient corresponds to the difference between the second row and the intercept, i.e., the difference between our control group post-Launch Day and our control group pre-Launch Day.
Recall that this is precisely our “control difference” — what we think would have happened to our treatment group if not for the WNI.
(III) The Permanent Difference
Now, what if it’s the opposite? What if “post-Launch Day” is zero but “received WNI” is one?
In this case, we’re considering all observations that come from our treatment group prior to Launch Day, i.e., the third row of our data set. And again, because this is a regression, the coefficient will correspond to the difference between our third row and our first row.
We haven’t commented on this quantity before, but it represents the “permanent difference” between our treatment and control groups.
Concretely, if this coefficient were positive, it would indicate that the classes in our treatment group generally instill higher levels of mastery than those in our control group. (This may not be crazy: What if more motivated professors were both more likely to implement our WNI and make better classes?)
That said, for our purposes, it’s not totally important to figure out why these differences exist — our parallel trends assumption seemed valid. As we’ll see, this quantity is here to make the math work as we calculate our final difference…
(IV) The Difference-in-Differences, i.e., The WNI Effect
Finally, we get to our raison d’etre, our coup de grace, our fourth row.
When both “post-Launch Day” is one and “received WNI” is one, we’re considering all observations that come from our treatment group after Launch Day.
The coefficient here represents the difference between this group and the sum of the quantities from (II) and (III), i.e., the control difference and the permanent difference.
In other words, we don’t want our estimated treatment effect to simply reflect fundamental differences between treatment and control, so our regression subtracts the permanent difference we calculated in (III). At this point, we’re left with the “Naive Treatment Effect” discussed earlier (which in our four-row data set corresponds to the difference between the third and fourth rows).
Of course, for the same reasons discussed earlier, this Naive Treatment Effect won’t do. We now need our regression to subtract the control difference we calculated in (II) to get our “real” treatment effect, i.e., the effect of our WNI absent seasonality and other platform-level changes.
Once we do, we get our coefficient of 6.14.
(V) Conclusion
What have we learned?
In this simple, four-row scenario, regression was nothing but a needlessly fancy subtraction engine! One whose results could have easily been calculated manually:
((dfg.loc[3, 'avg_learner_mastery'] - dfg.loc[2, 'avg_learner_mastery']) - (dfg.loc[1, 'avg_learner_mastery'] - dfg.loc[0, 'avg_learner_mastery'])) # prints 6.1459227998073231
Yup.
One more time for emphasis: Row Four minus Row Three is our “Naive Treatment Effect,” and Row Two minus Row One is our “Control Effect.” The difference between these two effects is our “Real Treatment Effect.” (Notice that when we do the calculation manually, we don’t have to worry about the “Permanent Difference,” as it naturally falls out when we take our first difference.)
To reiterate: Everything we do from here on out will simply be a variation on this painfully, almost insultingly basic idea!
Why go through all the pedantry?
Clearly, you’ve never read my blog!
Seriously, though I think it’s powerful to fully grok the simplest case before doing anything more complicated. Mostly, though, I wanted to emphasize this: All statistical techniques are, at their core, dumb! Dumb-dumb-dumb! We just dress them up with complicated terms and ritualistic silliness to hide the fact that we’re all self-conscious about the dumb things we’re doing!
Realizing this is one of the world’s most liberating feelings because it strips away all the pretense and leaves you with dumb — but also really, really powerful — tools.
Part 4: Difference-in-Differences with Only Two Observations per Class — One Before Launch Day and After Launch Day
While the simple approach above is fun (and hopefully intuitive!), it does have a problem: It doesn’t tell us whether we should take our effect “seriously” or not.
Luckily, we have a lot of courses, so we should be able to get some insight into whether we should. How? Well, regression isn’t only a needlessly fancy subtraction engine — it’s also a super-charged averaging machine, which comes standard with a statistical significance afterburner. (Notably, I have not heard back from the Fast and the Furious team about my pitch to make their next film statistics-themed.)
For this next example, we’re going to return to our original data set — no more aggregated, four-row silliness. However, we are going to collapse our data into two periods per class: “before Launch Day” and “after Launch Day.” By limiting ourselves to two periods, we can sidestep the messiness that arises from time series issues like autocorrelation. (But don’t worry! We’ll learn how to handle the real-world messiness in Part 5.)
# this time, group by class_number as well dfgg = df.groupby(['class_number', 'received_wni', 'post_launch_day']).mean().reset_index()
Now that we have our averaged data, we can fit virtually the same regression3 from Part 3, but with one twist: We’ll now include regressors for all of our individual classes instead of lumping everything into two big groups. This allows our regression to account for any permanent differences between all individual classes, and not just permanent differences between treatment and control groups in the aggregate. In general, this will lead to more precise, reliable estimates of the WNI effect, as our model won’t be confused by the massive variance in what it thinks are the same “class” of observation (“WNI” or “non-WNI”).
In code, it would look like this:
reg = smf.ols('avg_learner_mastery ~ post_launch_day + class_number + post_launch_day:received_wni',
dfgg).fit()
reg.summary()

And look! There’s our WNI treatment effect of 6.14. Easy-peasy!
(Note that since I like you, I’m only showing you the very bottom of the regression summary table — you don’t need to see coefficients for all 50 classes.)
As you can tell, now that we have an intuitive understanding of what difference-in-differences regression is actually doing, it’s become a simple matter to extend the approach to more complicated model specifications.
Part 5: Extending the Previous Model to Work for Time Series Data, i.e., Difference-in-Differences with Ten Observations per Class
Speaking of complicated… in many real-world cases, we really do have multiple time periods that we want to include in our analysis. For example, in our original data set, we had ten observations for every class — five before Launch Day and five after Launch Day.
And while this extra information can be nice, we need to use it responsibly: These kinds of repeated observations are synonymous with serial correlation.
Why is serial correlation a problem? I like this explanation, but I’ll try to add some color as well. (Note that this could probably be a whole post [and may be one soon!], so I’m going to keep it high-level.)
When you took undergraduate statistics, one of the things your professor probably did was list out the assumptions of regression inference and then fail to explain them properly (I kid, I kid).
One such assumption was this: Your errors can’t be correlated. In other words, knowing something about the error of one of your estimates should tell you nothing about the error of one of your other estimates.
However, this assumption breaks down in the presence of serial correlation. Why? Well, let’s consider a Calculus class from our data set. What would happen if — one random month — it became weirdly popular among Caltech students? Caltech students are pretty smart (source not cited), so Learner Mastery scores would probably go up. Moreover, Caltech students might be inclined to share this class with their network (whose members might also be smart), and so Learner Mastery scores in subsequent months would remain elevated. After a while, as students from Caltech and Caltech’s network got bored and moved on to classes about programming drones, Calculus mastery scores would return to normal. However, in all likelihood, a simple regression would systematically underestimate the scores during the “Caltech” months and systematically overestimate the scores during the “normal” months, as it tries to strike a balance between the two (remember: Regression is a super-charged averaging machine, but not a particularly smart one).
This is a violation of our regression assumptions, because if we knew that Month 2 was the first “Caltech month,” we would be able to say something about our probable error in Months 3 and 4.
Intuitively, then, serial correlation means we have less information than we think we do. Although we’re treating the monthly observations of this Calculus class independently, any observation that is touched by this Caltech effect is, in some sense, not a real independent observation.
This is not good. Regression will proceed to calculate our standard errors — the things which tell us how precise our estimates are and whether we should take them seriously — under overly optimistic assumptions4. It’ll think we can treat all ten error terms as wondrous, unique snowflakes, but in reality, we need to melt some of these snowflakes together to account for their connectedness.
So what can we do?
Thankfully, many smart people have thought about it, and their solutions are available in R and Python.
My preferred method (assuming you have enough unique classes in your data set5) is to fit the same regression6 from Part 4…
# we're in R now! m = lm(avg_learner_mastery ~ month + class_number + post_launch_day:received_wni, df) summary(m)

…but to use R’s multiwayvcov package or Python’s statsmodels to cluster7 by class. Clustering will adjust our standard errors by allowing for things like autocorrelation within a class, which helps address our “Caltech problem” along with other unobserved time trends.
# still in R!
vcov_class = cluster.vcov(m, df$class_number)
coeftest(m, vcov_class)
# now in Python!
reg = smf.ols('avg_learner_mastery ~ month + class_number + post_launch_day:received_wni', df)
reg = reg.fit(cov_type='cluster', cov_kwds={'groups': df['class_number']})
reg.summary()
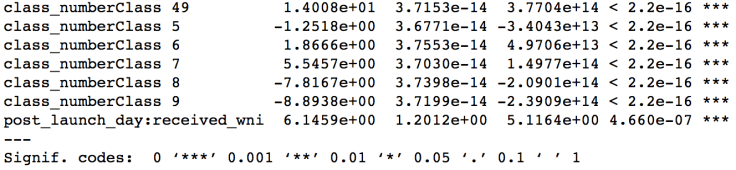
In the third column, we see that the standard errors of our WNI estimate increased: The adjustment has done its job.
(Having said all that, please never underestimate the power of simplicity — in either causal inference or life in general. One reasonable approach here would be to aggregate data into “pre” and “post” periods, and then this problem reduces to the simpler one we solved in Part 4. You give up a bit of statistical power — and you can’t get into heated Internet disputes about the right way to cluster — but then again: convenience! This tactic is particularly helpful — even necessary — when we don’t have enough higher-level groups for clustering to work properly. See the Appendix for more.)
Part 6: Wrapping Up with Panel Methods, or — Part 5 Is Your Generalizable Friend
In all of our previous analyses, we made a big simplifying assumption: Namely, that we had a single, action-packed “Launch Day” when the WNI happened.
This Launch Day allowed us to cleanly separate our data into “pre” and “post” periods, which has a number of convenient side effects: In Part 2, for example, we used this fact to visualize whether our assumption of parallel trends was valid. (If we wanted, we could have even done a little “analysis” by eyeballing how the difference between the green and blue lines changed over time.) Meanwhile, in Part 4, we didn’t have to include separate regressors for every month, and in Part 5, we could have simplified the problem by straightforwardly aggregating our ten monthly observations into two “before” and “after” observations.
Of course, the world isn’t always — or even mostly — so kind to us Data Scientists.
Consider, then, a world where professors could choose to implement the WNI at any time. Some professors implement it in January, while others don’t get around to it until June. Suddenly, we have treatments happening all over the place!
Is there any hope?
Yes!
Look closely at the regression equation from Part 5. It doesn’t actually make any assumptions about when the treatment variable is turned on because it includes separate regressors for every month (if you missed this, I cover it more explicitly in Note 6 of the Appendix). As such, even if different classes got the treatment at different times, we can use the exact same process from Part 5 to calculate the treatment effect of your WNI.
In other words, if you’ve made it this far, you have been rewarded. Part 5 is your generalizable friend, and will serve you well in all of your time-related inference endeavors.
This concludes my post. May the one you pine after never again forget what you did to win his or her heart.
And even if they have, code is still available.
In a future post, I hope to cover some things I didn’t get to here, like robustness checks and how to think about this problem with multilevel models.
Appendix
0Seriously, though, read Angrist and Pischke’s Mostly Harmless Econometrics or Mastering ‘Metrics for the real causal inference scoop.
Also, please don’t yell at me, Economists — this was just a silly joke! You’re much more than clever regression jockeys, and I know that regression specification is far from the most complicated part of the process!
1Obviously, IRL, an Online Education Platform would likely A/B test their WNI; however, for the purposes of this post, we’re assuming we can’t because all the engineers are busy.
Additionally, even though Learner Mastery is a nebulous term I never defined, you can imagine many ways to reformulate our central scenario to be more real-world:
- We work at {CLOTHING_RETAILER}. We have a bunch of {UNIQUE_STORES_IN_MALLS_ACROSS_AMERICA} and we’ve recently discovered a WNI that we think improves {SAME_STORE_SALES}.
- We work at {STATE_GOVERNMENT}. We have a bunch of {UNIQUE_COUNTIES} and we’ve recently discovered a WNI that we think improves {PUBLIC_HEALTH}.
- We work at {MOVIE_THEATER_CHAIN}. We have a bunch of {UNIQUE_MOVIE_THEATERS} and we’ve recently discovered a WNI that we think improves {TICKET_SALES_FOR_NON_SUPERHERO_MOVIES}.
- etc.
In all of these scenarios, an A/B test would be doubly impossible. It’s hard to imagine J. Crew randomly sending half of its shoppers into one part of the store and the other half into another part of the store. (Moreover, the resulting customer confusion from such a policy would certainly ruin the experiment.) Here, you would need the techniques from this post.
2Think about how cool this is!
If we can assume that — in the absence of our WNI — our treatment and control groups would have seen parallel changes in Learner Mastery, then we can estimate valid causal effects. This is true even if the treatment and control groups aren’t particularly “comparable” to one another.
To make this point concrete, let’s return to an extreme version of our New Year’s Resolution scenario. If we can assume that, on average, the “New Year’s Resolution” effect impacts all classes in parallel ways, then it wouldn’t matter if the treatment group included nothing but Computer Science classes and the control group included nothing but History classes. We could still use difference-in-differences to do causal inference.
This is the power of time!
It’s also a stark contrast to your typical regression scenario, where you generally need to assume you’ve controlled for everything important if you want to even whisper the word “effect.” By the way, this assumption is — to quote statistical philosopher Gwen Stefani — literally bananas (“B-A-N-A-N-A-S!”).
(Of course, whether we should take parallel trends seriously in the first place is a profound existential problem…
In general, parallel trends will be a much easier sell if the two groups are comparable, or if we can include regressors which control for critical differences. If we were doing a similar analysis on U.S. states, for example, we’d likely prefer to compare North Carolina to Virginia — not North Carolina to Hawaii. And if North Carolina and Hawaii were all we had, then hopefully we could include regressors for, say, demographic variables.
Moreover, there’s some additional subtlety here. Up until now, we’ve been saying we’re estimating the “Treatment Effect” of our WNI. However, what we’re really estimating is the “Treatment Effect on the Treatment Group.” In particular, because our treatment and control groups can be different from one another, we can’t really be sure that the WNI will impact all classes in the same way. For example, if we later rolled out our WNI to our control group, then it’s possible we’d see a totally different treatment effect. To uncreatively return to the Computer Science / History example… what if our WNI was a way to improve coding assignments!?)
3Another approach I really like is simply bootstrapping an estimate of the treatment effect. Indeed, I plan to write a love letter to bootstrapping very soon, but in the meantime…
classes = dfgg.class_number.unique()
num_classes = len(classes)
num_reps = 1000
result = np.zeros([num_reps, 1])
for i in xrange(num_reps):
tmp_classes = pd.DataFrame({'class_number': np.random.choice(classes, num_classes)})
tmp_df = tmp_classes.merge(dfgg, how='inner', on=['class_number'])
tmp_dfg = tmp_df.groupby(['received_wni', 'post_launch_day']).mean().reset_index()
post = (tmp_dfg['received_wni'] == 1) & (tmp_dfg['post_launch_day'] == 1)
pre = (tmp_dfg['received_wni'] == 1) & (tmp_dfg['post_launch_day'] == 0)
naive_treatment_difference = (tmp_dfg[post]['avg_learner_mastery'].iloc[0] -
tmp_dfg[pre]['avg_learner_mastery'].iloc[0])
post = (tmp_dfg['received_wni'] == 0) & (tmp_dfg['post_launch_day'] == 1)
pre = (tmp_dfg['received_wni'] == 0) & (tmp_dfg['post_launch_day'] == 0)
control_difference = (tmp_dfg[post]['avg_learner_mastery'].iloc[0] -
tmp_dfg[pre]['avg_learner_mastery'].iloc[0])
result[i] = naive_treatment_difference - control_difference
print "Bootstrap estimate of treatment effect: Median estimate of %.2f, 95%% CI from %.2f to %.2f" % (
np.percentile(result, 50),
np.percentile(result, 2.5),
np.percentile(result, 97.5))
# prints "Bootstrap estimate of treatment effect: Median estimate of 6.15, 95% CI from 3.94 to 8.26"
4Technically, this is only true for positive serial correlation. If we saw negative serial correlation, then the standard errors would be calculated under overly pessimistic assumptions. However, here I focus on the much more practical — and much more real-world — former case.
(That said, the method you’d use to account for serial correlation would be the same either way.)
5What’s “enough” unique classes? Let’s call it 42, per Angrist and Pischke’s Mostly Harmless Econometrics.
6You’ll notice it’s a little different — in particular, we now have separate regressors for every month instead of a simple “post” regressor. This controls for effects that are specific to individual months — say, March v. April v. June, and is analogous to the way we added class-level regressors when we went from Part 3 to Part 4.
7The other thing I love about multiwayvcov/statsmodels is that assuming we had enough unique months (again, let’s call it 42+) , it would be a simple matter to extend our clustering to work for month as well as class:
# in R!
vcov_both = cluster.vcov(m, cbind(df$class_number, df$month))
coeftest(m, vcov_both)
# in Python!
reg = smf.ols('avg_learner_mastery ~ month + class_number + post_launch_day:received_wni',
df)
reg = reg.fit(cov_type='cluster', cov_kwds={'groups': np.array(df['month'], df['class_number'])})
reg.summary()
# (see also the "hac-panel" correction from the statsmodels link)
Why would we do this? Well, in the same way the Caltech Problem could plague a given class over time, it’s possible that an analogous effect could plague a given time period across classes.
To see this, let’s pretend a bunch of Martians land on Earth in January and join our platform. Let’s also pretend that they want to catch up on all of human history, so they only take history classes.
Let’s further assume that as hyper-rational space travelers, these Martians do spectacularly poorly on all of their exams: They simply can’t imagine anything in the universe behaving as irrationally as humans do, and indeed — they’re so traumatized by the correct answers that they leave not only our platform but the entire Milky Way Galaxy the following month.
The cosmic upshot: For the month they’re on the platform, our Martian visitors bring down Mastery scores in all of the classes that they join. Here, our regression assumptions would again be violated, since knowing something about the error in European History would tell you something about the probable error in Nero’s Guide to Ancient Rome.
In this case, two-way clustering would be your friend. And although we didn’t use it in our example, I did want to make you aware of this problem and ensure that the solution was in your arsenal.
8The general way to accomplish this is:
- Regress Learner Mastery on month and class (or whatever your time and group dimensions happen to be)
- Save the residuals from this regression
- For all the classes that received your WNI, regress this residual on whether it is associated with a pre-Launch Day observation or a post-Launch Day observation
Or… since code > words:
df_resid = df.copy()
reg = smf.ols('avg_learner_mastery ~ month + class_number', df_resid).fit()
df_resid['resid_learner_mastery'] = df_resid.avg_learner_mastery - reg.predict(df_resid)
reg_resid = smf.ols('resid_learner_mastery ~ post_launch_day', df_resid[df_resid.received_wni == 1]).fit()
reg_resid.summary()

May 1, 2017 at 8:27 pm
statsmodels has robust covariance matrices available by specifying the cov_type keyword in fit, including one-way and two-way cluster and several panel robust sandwiches, besides HAC and standard HC. All Wald type inference will then be based on the chosen cov_type.
LikeLike
May 1, 2017 at 9:07 pm
Ah, awesome — thanks for flagging! (And my apologies for missing this in the first place — I can’t believe I didn’t catch this!)
I will update this post now to make note of this and include some code examples.
LikeLike
May 1, 2017 at 9:27 pm
Made the changes! (using statsmodels for the job was wonderfully simple 🙂
LikeLike
May 6, 2021 at 3:55 pm
Thanks for this enlightening post. It’s one of the few things I’ve read on this topic that has made so much sense! I had one question, though. There’s a footnote at the bottom numbered 8 (“The general way to accomplish this is”) but I couldn’t find a reference to it in the body of the post.
LikeLike
July 10, 2022 at 8:55 pm
Thank you so much for the kind words, and apologies for not responding sooner! It seems WordPress’s comments weren’t working for me.
Embarrassingly, I couldn’t figure out what I was referring to until I re-read the whole post :’)
That footnote was supposed to go with this paragraph:
(Having said all that, please never underestimate the power of simplicity — in either causal inference or life in general. One reasonable approach here would be to aggregate data into “pre” and “post” periods, and then this problem reduces to the simpler one we solved in Part 4. You give up a bit of statistical power — and you can’t get into heated Internet disputes about the right way to cluster — but then again: convenience! This tactic is particularly helpful — even necessary — when we don’t have enough higher-level groups for clustering to work properly. See the Appendix for more.)
LikeLike